[toc]
经过ga1axy师傅的一些指导,发现以前刷题数量不足,且对原理了解不够充分,过分依赖在线工具。很多东西看似有所了解,实则没有深入。所以想要在此记录一下未来几个月BUUCTF上的刷题记录和一些联想到的知识点,希望几个月后能有所进步。
此篇文章记录BUUCTF解出人数>=100人的题目(部分没有营养的题目会省略)。
[V&N2020 公开赛]拉胯的三条命令
payload:
tcpdump -n -r nmapll.pcapng 'tcp[13] = 18' | awk '{print $3}'| sort -u
awk{print $3} 输出 第三个字段
sort -u 去掉重复
tcpdump抓取TCP标识位:
按每8位组算,TCP的标志位位于第13个8位组中,如下,第一行一共32位是0 - 3个8位组,第二行是4-7八位组,第三行是8-11八位组,data offset +reserved的前四个是第12个8位组,reserved中的后2位+6个标志位是第13个八位组。
以下TCP报头

因此第13个八位组结构为
- - + + + + + +
前面2个是保留的,都为0,后面的6个根据不同情况有不同值,例如syn 包 则为
00 0 0 0 0 1 0
这是二进制转化为十进制就是2
因此 tcpdump -ni eth0 tcp[13]==2 就表示syn包。
同理,syn+ack包为
00 0 1 0 0 1 0
化为十进制就是18,因此tcpdump -ni eth0 tcp[13]==18 表示syn+ack包。
如果想同时抓syn和syn+ack包,则进行tcp[13]位值与掩码进行与运算:
tcp[13] & 2 == 2
我吃三明治
一开始尝试分离图片,后发现没有什么特别的地方。
用winhex打开原图片,在两张图片连接处发现base32编码数据

base32解码后即为flag
[ACTF新生赛2020]NTFS数据流
下载后获得一个压缩包,解压压缩包,利用ntfsstreamseditor扫描即可得到flag


[SUCTF2018]single dog
分离图片得到一个未加密的压缩包,打开后是一个颜文字加密
颜文字解密方法:
打开浏览器控制台,复制加密后的颜文字代码并去掉末尾的(‘_’),最后回车执行。
解密后得到flag

[DDCTF2018](╯°□°)╯︵ ┻━┻

将这串数据,两位两位组成十六进制数,再对128求余,即可得到答案
从娃娃抓起
0086 1562 2535 5174 中文电码
人 工 智 能
bnhn s wwy vffg vffg rrhy fhnv 五笔编码
也 要 从 娃 娃 抓 起[ACTF新生赛2020]swp

在http流中看到一个secret.zip文件,但是不知道什么原因,我在导出后一直显示压缩包已损坏,于是尝试手动提取文件。

在tcp.stream eq 96中,将数据用原始数据显示,并从504B0304开始复制到结尾

全部复制到winhex中,保存文件,有一个伪加密。

将伪加密去掉后即可得到flag
[GUET-CTF2019]zips
下载得到一个222.zip加密压缩包,爆破后获得密码得到一个111.zip。111.zip有一个伪加密,将09改成00消除伪加密。


用python2运行此代码,能发现时间戳的格式。(一开始尝试了python3的,后发现数字实在太长,感觉不可能,就换成python2了)

利用掩码 16????????.?? 爆破flag.zip压缩包,爆破了6分钟后发现没找到密码。后想到出题的时候可能是15开头的时间,所以将掩码改成15????????.??,爆破出flag.zip的密码,得到flag。

[MRCTF2020]千层套路
下载后获得一个套娃压缩包,根据hint可知压缩包密码为压缩包名字,写几个类似的解压缩包脚本
import zipfile
import os
file_path = "0573.zip"
while 1:
zipFile = zipfile.ZipFile(file_path)
(filepath,tempfilename) = os.path.split(file_path)
(filename,extension) = os.path.splitext(tempfilename)
try:
zipFile.extractall(pwd= bytes(filename, "utf8" ))
print("破解成功,密码为: " + filename)
print(zipFile.namelist())
file_path = "".join(zipFile.namelist())
except:
break
# -*- coding:utf-8 -*-
import zipfile # 引入zipfile模块
name = '0573.zip'
passwd = b'0573' #密码需要b''样式的字符串
while (1):
with zipfile.ZipFile(name) as zFile: # 创建ZipFile对象指定需要解压的zip文件
zFile.extractall(path='./', pwd=passwd)
name = zFile.filelist[0].filename
if name[-3:-1] != 'zi': #如果文件后缀不是zip了就停止
break
passwd = bytes(name[0:4], 'utf-8')
# print('Extract the Zip file successfully!')
最终可以获得一个坐标颜色的txt文件,写一个画图脚本,得到二维码扫描即可获得flag
from PIL import Image, ImageDraw, ImageFont, ImageFilter
f1 = open(r'qr.txt','r')
width = 200
height = 200
image = Image.new('RGB', (width, height), (255, 255, 255))
draw = ImageDraw.Draw(image)
for i in range(0,height):
for j in range(0,width):
s = f1.readline()
s = s.strip('\n')
if not s:
break
if s == "(255, 255, 255)":
draw.point((i, j), fill=(255,255,255))
else:
draw.point((i, j), fill=(0,0,0))
image.show()
USB

将7A A0改成74 A0,修复png压缩头。
参考:https://www.freebuf.com/column/199854.html
用stegsolve打开png图片,可得到一个二维码:

扫码得 ci{v3erf_0tygidv2_fc0}
binwalk一下key.ftm文件,可以得到key.pcap文件。
tshark可以分离出按键数据
tshark -r key.pcap -T fields -e usb.capdata>out.txt

利用UsbKeyboardDataHacker可得到键盘按键信息,得到key:xinan

利用维吉尼亚密码,将刚才得到的字符串解密:fa{i3eei_0llgvgn2_sc0}
再利用栅栏密码移位2,得到最终flag:flag{vig3ne2e_is_c00l}
USB一些操作:
descriptor response device 记录设备信息,搜索关键字DESCRIPTOR
[SWPU2019]Network
下载得到一串四个四个数字一直重复的数据。
通过观察可知,63的8进制为077,127的8进制为177,191的8进制为277,255的8进制为377.他们只有开头不一样,而且只有0 1 2 3的区别,猜测跟二进制有关。利用脚本跑一遍得到二进制数据。
f = open("attachment.txt","r")
s = ''
tmp = ''
while 1:
num = f.readline()
if not num:
break
if num.rstrip() == '63':
tmp = '00'
elif num.rstrip() == '127':
tmp = '01'
elif num.rstrip() == '191':
tmp = '10'
elif num.rstrip() == '255':
tmp = '11'
s += tmp
print(s)跑一遍后得到二进制数据,利用CyberChef转储成十六进制数据,发现是个压缩包文件,然后将十六进制转成文件数据,得到压缩包文件。


打开压缩包后里面是一个很长的base64编码,循环利用base64解码,最终可以获得flag。
以下附上python一把梭生成压缩包脚本,供以后学习:
fp = open('attachment.txt','r')
a = fp.readlines()
p = []
for i in a:
p.append(int(i))
s = ''
for i in p:
if i == 63:
a = '00'
elif i == 127:
a = '01'
elif i == 191:
a = '10'
elif i == 255:
a = '11'
s += a
import binascii
flag = ''
for i in range(0,len(s),8):
flag += chr(int(s[i:i+8],2))
flag = binascii.unhexlify(flag)
wp = open('ans.zip','wb')
wp.write(flag)
wp.close()蜘蛛侠呀
下载下来获得一个pcap文件,利用tshark分离出原始数据
tshark -r out.pcap -T fields -e data >out.txt
然后利用脚本将原始数据改成十六进制数据
lines = open("out.txt",'rb').readlines()
files = open("out1.txt","wb")
for line in lines:
files.write(line.strip().decode('hex'))
files.close()
#python2
将第一行尝试base64解码,发现有zip的头文件,尝试将每行都base64解码:
import base64
lines = open("out1.txt",'rb').readlines()
file1 = open("out2.zip",'wb')
result = ''
for line in lines:
result += line[9:].strip()
file1.write(base64.b64decode(result))解码后发现每块数据都重复了四次,利用脚本去掉重复数据并写入out.zip文件:
import base64
lines = open("out1.txt",'rb').readlines()
file1 = open("123.zip",'wb')
result = ''
i = -1
for line in lines:
i += 1
bb = lines[i].strip()
if bb == lines[i-1].strip():
continue
result += line[9:].strip()
file1.write(base64.b64decode(result))
#python2得到一个看起来帧数很低的gif文件,感觉跟停顿时间有关,利用identify获取数据:
identify -format “%T” flag.gif
“20”“50”“50”“20”“50”“50”“20”“50”“20”“50”“20”“20”“20”“50”“20”“20”“20”“20”“50”“50”“20”“50”“20”“50”“20”“50”“20”“50”“50”“50”“50”“50”“20”“20”“50”“50”“20”“20”“20”“50”“20”“50”“50”“50”“20”“50”“20”“20”“66”“66”将20转化成0,50转化成1,binary转asc码即可然后md5加密即可得到flag
脚本一把梭:
import hashlib
import binascii
a="205050205050205020502020205020202020505020502050205020505050505020205050202020502050505020502020"
flag = '0b'
for i in range(0,len(a),2):
if a[i:i+2] == '20':
flag += '0'
if a[i:i+2] == '50':
flag += '1'
flag1 = hex(int(flag,2))[2:]
print(flag1)
flag2 = bytes.fromhex(flag1).decode()
print(flag2)
flag = hashlib.md5(flag2.encode("utf-8")) .hexdigest()
print(flag)6d44355f3174
mD5_1t
f0f1003afe4ae8ce4aa8e8487a8ab3b6[RCTF2019]draw
下载获得一个txt文件:
cs pu lt 90 fd 500 rt 90 pd fd 100 rt 90 repeat 18[fd 5 rt 10] lt 135 fd 50 lt 135 pu bk 100 pd setcolor pick [ red orange yellow green blue violet ] repeat 18[fd 5 rt 10] rt 90 fd 60 rt 90 bk 30 rt 90 fd 60 pu lt 90 fd 100 pd rt 90 fd 50 bk 50 setcolor pick [ red orange yellow green blue violet ] lt 90 fd 50 rt 90 fd 50 pu fd 50 pd fd 25 bk 50 fd 25 rt 90 fd 50 pu setcolor pick [ red orange yellow green blue violet ] fd 100 rt 90 fd 30 rt 45 pd fd 50 bk 50 rt 90 fd 50 bk 100 fd 50 rt 45 pu fd 50 lt 90 pd fd 50 bk 50 rt 90 setcolor pick [ red orange yellow green blue violet ] fd 50 pu lt 90 fd 100 pd fd 50 rt 90 fd 25 bk 25 lt 90 bk 25 rt 90 fd 25 setcolor pick [ red orange yellow green blue violet ] pu fd 25 lt 90 bk 30 pd rt 90 fd 25 pu fd 25 lt 90 pd fd 50 bk 25 rt 90 fd 25 lt 90 fd 25 bk 50 pu bk 100 lt 90 setcolor pick [ red orange yellow green blue violet ] fd 100 pd rt 90 arc 360 20 pu rt 90 fd 50 pd arc 360 15 pu fd 15 setcolor pick [ red orange yellow green blue violet ] lt 90 pd bk 50 lt 90 fd 25 pu home bk 100 lt 90 fd 100 pd arc 360 20 pu homelogo语言
logo语言资料:https://personal.utdallas.edu/~veerasam/logo/
在线解释器:https://www.calormen.com/jslogo/


输入txt文件中的代码即可获得flag
[SUCTF2018]followme
直接搜索SUCTF的十六进制即可得到flag

通过流量可知,有很多的404和不同的目录,这个pcap文件保存的是爆破目录和账号密码等的数据

[MRCTF2020]不眠之夜
利用gaps进行自动拼图
montage *jpg -tile 10x12 -geometry 200x100+0+0 out.jpg #先执行montage拼成一个图片
# 将目录中的jpg文件按顺序拼成x轴10块,y轴12块,每个图块大小为200x100像素,输出文件为out.jpg
gaps --image=out.jpg --generations=50 --population=120 --size=100 #还原原图片
--image 指向拼图的路径
--size 拼图块的像素尺寸
--generations 遗传算法的代的数量
--population 个体数量
--verbose 每一代训练结束后展示最佳结果
--save 将拼图还原为图像
[GKCTF2020]code obfuscation
先binwalk一下,能拿到一个加密过的压缩包。
下载得到一个斜着的并打了白条的二维码,花了好长时间用PS手动修复后,扫码得到文本 base(gkctf),然后利用各种base码尝试过去,发现base58是正确答案,CfjxaPF
解开压缩包后得到一张图片和一串js代码,利用在线网站自动排版并解密,然后自己整理一下,得到:

for n in a b c d e f g h i j k l m n o p q r s t u v w x y z do eval An = "n"
done
for n in A B C D E F G H I J K L M N O P Q R S T U V W X Y Z do eval An = "n"
done num = 0
for n in a b c d e f g h i j do eval Bn = "n"
num = $((num + 1))
done alert("Bk=' ';Bm='"';Bn='#';Bs='(';Bt=')';By='.';Cb='';Cc='<';Ce='>';Cl='_';Cn='{';Cp='}';Da='0';Db='1';Dc='2';Dd='3';De='4';Df='5';Dg='6';Dh='7';Di='8';Dj='9';")
写一个python脚本解码:
s="Bn$Ai$An$Ac$Al$Au$Ad$Ae$Bk$Cc$As$At$Ad$Ai$Ao$By$Ah$Ce$Ai$An$At$Bk$Am$Aa$Ai$An$Bs$Bt$Cn$Ap$Ar$Ai$An$At$Bs$Bm$Aw$Dd$Al$Ac$Da$Am$Ae$Cl$De$Ao$Cl$Dj$Ak$Ac$At$Df$Bm$Bt$Cb$Ar$Ae$At$Au$Ar$An$Bk$Da$Cb$Cp"
list = s.split('$')
dict = {'Bk':' ','Bm':'"','Bn':'#','Bs':'(','Bt':')','By':'.','Cb':'','Cc':'<','Ce':'>','Cl':'_','Cn':'{','Cp':'}','Da':'0','Db':'1','Dc':'2','Dd':'3','De':'4','Df':'5','Dg':'6','Dh':'7','Di':'8','Dj':'9'}
flag = ""
for i in range(len(list)):
if list[i][0] == "A":
flag += list[i][1]
else:
flag += dict[list[i]]
print(flag)解得结果为:
#include <stdio.h>int main(){print("w3lc0me_4o_9kct5")return 0}[安洵杯 2019]easy misc
下载文件,有一个很多英文txt的文件夹,一个加密压缩包和一张图片。先看一下压缩包,有一个备注:
FLAG IN ((√2524921X85÷5+2)÷15-1794)+NNULLULL,一开始以为X是未知数,让我们自己随机取的,然后再加上后面的字符串得到密码,但是0-9全部试了一遍都不对。后来把X看作是乘,果然就对了,得到答案7。尝试掩码爆破,最终得到压缩包密码

得到一些数据,通过txt名字decode可知是用来解密的数据。
a = dIW
b = sSD
c = adE
d = jVf
e = QW8
f = SA=
g = jBt
h = 5RE
i = tRQ
j = SPA
k = 8DS
l = XiE
m = S8S
n = MkF
o = T9p
p = PS5
q = E/S
r = -sd
s = SQW
t = obW
u = /WS
v = SD9
w = cw=
x = ASD
y = FTa
z = AE7
binwalk图片可以得到两张看起来相同的图片,尝试异或和盲水印,最终可得是盲水印隐写。
这里有一点要注意的就是,python2和python3的盲水印加密方式是不一样的,这题用python3的解密脚本得不到答案,用python2的解密脚本就可以得到答案了。由于python3的脚本里自带python2的解密方法,故利用--oldseed即可。
python bwmforpy3.py decode 1.png 2.png flag.png #python3
python bwmforpy3.py decode 1.png 2.png flag.png --oldseed #python2
得到hint,in 11.txt。由于之前得到的decode.txt中有字母和字符串的对应,所以尝试词频分析11.txt。
词频分析脚本:
import re
file = open('11.txt')#读取文件的路径
line = file.readlines()
file.seek(0,0)
file.close()
result = {}#使用字典来保存查询信息
for i in range(97,123):#26位小写字母
count = 0
for j in line:
find_line = re.findall(chr(i),j.lower())#查找出每一行匹配的字母,先转换小写再比对
count += len(find_line)#把每一行的查询结果数相加
result[chr(i)] = count#向字典存入每个字母的最终查询的结果
res = sorted(result.items(),key=lambda item:item[1],reverse=True)#对字典的value进行排序,降序,res是一个可迭代对象
num = 1
for x in res:#递归输出一下字典的每一个元素
print('频数第{0}: '.format(num),x)
num += 1
得到答案:
频数第1: ('e', 39915)
频数第2: ('t', 29048)
频数第3: ('a', 26590)
频数第4: ('o', 26141)
频数第5: ('h', 22531)
频数第6: ('n', 21825)
频数第7: ('r', 21650)
频数第8: ('i', 20815)
频数第9: ('s', 19714)
频数第10: ('d', 16617)
频数第11: ('l', 14594)
频数第12: ('u', 9755)
频数第13: ('g', 8619)
频数第14: ('y', 8619)
频数第15: ('w', 8397)
频数第16: ('m', 7394)
频数第17: ('f', 6857)
频数第18: ('c', 6696)
频数第19: ('p', 5548)
频数第20: ('b', 5328)
频数第21: ('k', 4009)
频数第22: ('v', 2908)
频数第23: ('q', 420)
频数第24: ('x', 383)
频数第25: ('j', 370)
频数第26: ('z', 264)按照WP,之后base64解码再base85解码就能得到flag了,可是我对照decode.txt的时候并不能获得base64编码,不知道是什么原因,就先搁置在这吧。
[XMAN2018排位赛]通行证
题目得到一个base64码
a2FuYmJyZ2doamx7emJfX19ffXZ0bGFsbg==先base64解码:
kanbbrgghjl{zb____}vtlaln然后W型栅栏密码,加密,key7:
kzna{blnl_abj_lbh_trg_vg}最后凯撒密码解密,key13:
xman{oyay_now_you_get_it}派大星的烦恼
整个图片中只有这一个比较特殊的地方:

通过长度计算可知 " 和 D 加起来一共有256个字符,题目提示flag有32个字符,而256/32=8,可知可能是8位二进制。
将 " 改成 1 , D 改成 0 ,但是解出来并没有结果,尝试0和1互换,还是没有结果

尝试将原数据倒序输出成01字符串,可以发现能解出答案,但是提交flag还是出错

a='"DD"DD""""D"DD""""""DD"""DD"DD""D""DDD""D"D"DD""""""DD""D""""DD"D"D"DD""""D"DD""D"""DD"""""DDD""""D"DD"""D"""DD"""D""DD"D"D"DD"""DD""DD"D"D""DD""DD"DD"""D"""DD""DD"DD""D"D""DD"D"D"DD"""D"""DD"""D"DD""DD"""DD"D"D""DD"""D"DD""DD""DD"""""DDD""DD""DD"""D""DD""'
b = ''
for i in range(len(a)-1,-1,-1):
if a[i] == '"':
b += '0'
else:
b += '1'
print(b)
最后尝试将flag再次倒序,提交后答案正确
[GKCTF2020]Harley Quinn
一共有两个hint:
hint:电话音&九宫格
FreeFileCamouflage,下载的文件可能显示乱码根据hint可知,音乐跟电话音有关,在音乐最后5秒左右有一串电话音,分离出来利用dtmf2num.exe识别:

根据hint九宫格和电话音解码得到的数字,可知是九键键盘,得到key:ctfisfun
然后根据第二个hint,尝试用hint中的工具解密:

得到一个flag.txt,里面就有flag
[MRCTF2020]Unravel!!
下载题目可以得到三个文件,一个加密的压缩包,一个音频文件,一个图片。
先对我比较熟悉的图片进行操作。用winhex打开发现最后有zip头文件,利用binwalk分离文件,获得一张名为aes.png的图片,图片上写着Tokyo。
用winhex打开wav文件,文件最后写着 key=U2FsdGVkX1/nSQN+hoHL8OwV9iJB/mSdKk5dmusulz4=
这串密码开头为U2F,又通过aes.png的文件名可知这是AES加密,利用AES解密,得到 CCGandGulu,解密压缩包得到另一个wav文件,但是没有任何声音。
拖到SilentEye里,直接得到flag了

[ACTF新生赛2020]明文攻击
用winhex打开woo.jpg,能发现有一个隐藏zip文件,但是头文件缺失了。修复头文件后用binwalk分离出了一个flag.txt的压缩包。

加密的原压缩包文件中也有一个flag.txt文件,利用明文攻击解密(不知道为什么,解的速度好慢啊):

保存解密后的压缩包即可获得flag
[MRCTF2020]Hello_ misc
下载文件得到一张图片和一个加密压缩包,binwalk一下图片,又能得到一个加密的压缩包。利用zsteg能发现还有一张png图片

利用命令分离图片:
zsteg -E "b1,bgr,lsb,xy" encode.png > de.png但是分离不出来,十六进制乱码了,具体原因也不知道为什么,查了下资料可能是因为这种图片只隐写了R通道,所以zsteg不出来。利用steagslove可以分离出图片,得到压缩包密码。

得到一个只有63,127,191,255的txt文件,通过以前做过的题目可知,大概率是八进制开头0 1 2 3的区别。利用脚本解码:
fp = open('out.txt','r')
a = fp.readlines()
p = []
for i in a:
p.append(int(i))
s = ''
for i in p:
if i == 63:
a = '00'
elif i == 127:
a = '01'
elif i == 191:
a = '10'
elif i == 255:
a = '11'
s += a
import binascii
flag = ''
for i in range(0,len(s),8):
flag += chr(int(s[i:i+8],2))
print(flag)
解得:rar-passwd:0ac1fe6b77be5dbe
解开压缩包,发现里面有个zip文件,打开看里面的文件知道了这是一个word文档,更改后缀名为doc,重新打开文件。发现有一些空白的但是有数据的地方

将这块地方改成红色,可以看到有一些字符串。

这些很明显是0和1的base64编码,利用base64解码,得到:
110110111111110011110111111111111111111111111111101110000001111111111001101110110110001101011110111111111111111111111111111111101111111111111110110011110000101110111011110111111100011111111111001001101110000011111000011111111110110100001111011110111111011101111111110110110101111111100110111111111111110110101111111011110111101011101111111110110110101101111100110111111111111110110100001100000110000001100011100000110110110101110000001111000011111111试了好几种方法也不知道是什么东西,后来尝试逐行解码才发现了一点特别的地方,这题脑洞真大,不愧是galaxy师傅。
110110111111110011110111111111111111111111111111101110000001111111111001101
110110110001101011110111111111111111111111111111111101111111111111110110011
110000101110111011110111111100011111111111001001101110000011111000011111111
110110100001111011110111111011101111111110110110101111111100110111111111111
110110101111111011110111101011101111111110110110101101111100110111111111111
110110100001100000110000001100011100000110110110101110000001111000011111111
将1替换成空白即可看到flag

word的间距不修改的话会有一点小瑕疵,但不影响肉眼观察,试几次错后得到flag:
flag{He1Lo_mi5c~}
[UTCTF2020]docx
打开docx文件,发现很长,按照以往的经验来看,应该是不会有flag直接写在文档里的。修改docx后缀为zip,查看压缩包里的内容。在media文件夹里可以看到一张flag图片,即可拿到flag

[WUSTCTF2020]spaceclub
下载得到一个txt,里面全是空格,但是每行空格的长度只有两种情况,尝试转化为0 1

fp = open('attachment.txt','r')
a = fp.readlines()
p = ""
for i in range(len(a)):
if len(a[i]) < 10 :
p += '0'
else:
p += '1'
print(p)
得到一串二进制字符串:
011101110110001101110100011001100011001000110000001100100011000001111011011010000011001101110010011001010101111100110001011100110101111101111001001100000111010101110010010111110110011001101100010000000110011101011111011100110011000101111000010111110111001100110001011110000101111101110011001100010111100001111101转化为asc码即可获得flag:
wctf2020{h3re_1s_y0ur_fl@g_s1x_s1x_s1x}
[BSidesSF2019]zippy
下载文件得到一个流量包。流量包里只有两段tcp数据,第一段可以获得一个压缩包密码:

第二段是压缩包文件,可以直接导出,利用第一个tcp流量里的密码解码即可获得flag
[UTCTF2020]file header
通过题目名就可以得知这题跟文件头有关,下载获得一个png文件,但是打不开。用winhex打开可以发现缺少头文件,修复后即可获得flag(原来有很多100多解的题也是水题啊)
[湖南省赛2019]Findme
下载下来有五张图片,第一张图片的显示有问题,测试可以是宽高错误。
跑脚本得到:
宽为:bytearray(b'\x00\x00\x00\xe3')
高为:bytearray(b'\x00\x00\x01\xc5')但是图片文件还是会出问题

用010editor打开,可以发现chunk2和chunk3缺少IDAT标识符,加上即可正常显示图片。用stegsolve打开即可看到一个二维码,扫码得到flag第一部分的base64编码

用记事本打开第二张图片,会发现里面有很多爆破txt的数据,在618.txt中找到第二部分flag

再用010editor打开第三张图片,可以在chunk当中发现每个crc数据块的值asc解码后都是数字和字母

解码后得:3RlZ30=
第四张图,末尾就有flag:cExlX1BsY,由于第三张图片已经有等号出现,而base64编码的字符串中间是不可能出现等号的,所以第四张这里的等号并不属于flag字符串中

第五张图片也是末尾就有flag:Yzcllfc0lN

总结一下:
flag1:ZmxhZ3s0X3
flag2:1RVcmVfc
flag3:3RlZ30=
flag4:cExlX1BsY
flag5:Yzcllfc0lN
多试几次,按照1 5 4 2 3的顺序,得到base64:
ZmxhZ3s0X3Yzcllfc0lNcExlX1BsY1RVcmVfc3RlZ30=
解码得到flag:flag{4_v3rY_sIMpLe_PlcTUre_steg}
在做到这题之前我几乎都不用010editor,因为功能比较多,导致界面相对比winhex会比较复杂。然后我对png的一些数据块头之类的又不是特别熟悉,所以做这题有点吃力。再用010editor后才方便不少。主要还是得再多熟悉一下png的各个数据块。
[GWCTF2019]huyao
这题把我做崩溃了,虽然不是脑洞把我搞崩溃了,但是这安装opencv-python把我搞崩溃了。下载文件可以得到两张一样的图片,一开始我先尝试盲水印和异或,但是都不对。于是查资料得知是频域盲水印,网上下载下来一个脚本:
# coding=utf-8
import cv2
import numpy as np
import random
import os
from argparse import ArgumentParser
ALPHA = 5
def build_parser():
parser = ArgumentParser()
parser.add_argument('--original', dest='ori', required=True)
parser.add_argument('--image', dest='img', required=True)
parser.add_argument('--result', dest='res', required=True)
parser.add_argument('--alpha', dest='alpha', default=ALPHA)
return parser
def main():
parser = build_parser()
options = parser.parse_args()
ori = options.ori
img = options.img
res = options.res
alpha = options.alpha
if not os.path.isfile(ori):
parser.error("original image %s does not exist." % ori)
if not os.path.isfile(img):
parser.error("image %s does not exist." % img)
decode(ori, img, res, alpha)
def decode(ori_path, img_path, res_path, alpha):
ori = cv2.imread(ori_path)
img = cv2.imread(img_path)
ori_f = np.fft.fft2(ori)
img_f = np.fft.fft2(img)
height, width = ori.shape[0], ori.shape[1]
watermark = (ori_f - img_f) / alpha
watermark = np.real(watermark)
res = np.zeros(watermark.shape)
random.seed(height + width)
x = range(height / 2)
y = range(width)
random.shuffle(x)
random.shuffle(y)
for i in range(height / 2):
for j in range(width):
res[x[i]][y[j]] = watermark[i][j]
cv2.imwrite(res_path, res, [int(cv2.IMWRITE_JPEG_QUALITY), 100])
if __name__ == '__main__':
main()
但是这个脚本是python2的,我的python2还没有装cv2。于是一开始我尝试修改脚本,使得python3可以跑,但是跑完之后没显示flag。又想着在虚拟机里搭python2的cv2,频频报错。最后经过好几个小时,才回到正轨,在网上下载了一个opencv-python-cp27的whl文件,然后安装完毕。
虽然这题跑出来就可以得到flag,但着实让我印象深刻。而且这也是我第一次接触频域盲水印,新知识get。
以下是我的物理机环境代码:
F:\python27\python2.exe BlindWaterMarkplus.py --original huyao.png --image stillhuyao.png --result res.png解得:

GWHT{BWM_1s_c00l}
Business Planning Group
下载下来得到一个png图片,利用stegsolve看看,没发现什么特殊的东西。
利用zsteg看看文件信息,发现了BPG文件

但是binwalk和foremost都分离不出来,于是利用winhex分离。在zsteg中能看出BPG的头文件是42 50 47 FB,在winhex中搜索到后,结束选块选择最后,分离文件

但是win10自带的图片查看器打不开BPG图片,不知道是我设置的问题还是本身就打不开。利用honeyview打开文件:

最终base64解码即可获得flag,这里有一点要注意的就是字符 'L',在图片中的这种字体,大写的‘i’和小写的‘L’,他们长得是一样的,这里让我试错了很多次。
[UTCTF2020]zero
一开始以为是利用quipquip解码,zero是啥key来着。后来尝试无果,用左右键在字符串上选数据的时候发现,有零宽字节。这时候再看这个题目,确实是zero。利用零宽字节即可直接获得flag:

但是一开始我在另一个在线网站上解不了,后来看了galaxy师傅的博客才明白。
galaxy师傅博客:http://www.ga1axy.top/index.php/archives/20/
每一种基于零宽度字符的隐写都可以有自己的隐写方式及加密方式,所以可能用这一个工具(或脚本)加密过的字符串在另一个解密网站就无法成功解密。
我以前常用的在线网站就没法解这题,得找另一个才可以。这题用的是第一个
在线解密1:http://330k.github.io/misc_tools/unicode_steganography.html
在线解密2:https://offdev.net/demos/zwsp-steg-js
在线解密3:https://yuanfux.github.io/zero-width-web/
[QCTF2018]X-man-A face

补全二维码即可,扫描得到:
KFBVIRT3KBZGK5DUPFPVG2LTORSXEX2XNBXV6QTVPFZV6TLFL5GG6YTTORSXE7I=base32解码得到flag:
QCTF{Pretty_Sister_Who_Buys_Me_Lobster}[ACTF新生赛2020]剑龙
打开压缩包得到三个文件。先打开passwd文件,发现颜文字加密

在谷歌控制台上输入,得到:

有JPG文件又有password,尝试jphide和steghide。通过测试可知是steghide,输入密码得到一个secret.txt文件


看字符串开头的U2Fsd可以把密码范围缩小到AES,DES,RC4等等

在jpg文件属性中可以看到密钥,利用DES解码得到:

think about stegosaurus在github上搜索stegosaurus,需要注意的是REAMDE中表述了只能解pyc,py,pro文件,所以需要改一下后缀名。解码即可获得flag
python stegosaurus.py -x O_O.pycpyc头文件标志为33 0D 0D 0A,在记事本中显示为3 。
[MRCTF2020]pyFlag
下载文件得到三张图片,在文件尾都发现了PK字样,即为zip文件。binwalk可以分离出Setsuna.jpg里的压缩包,有密码。爆破密码可得密码为1234,解压得到hint.txt:
我用各种baseXX编码把flag套娃加密了,你应该也有看出来。
但我只用了一些常用的base编码哦,毕竟我的智力水平你也知道...像什么base36base58听都没听过
提示:0x10,0x20,0x30,0x55但是只有hint没有加密文件。重新查看winhex:查看三个文件后面的数据,发现zip数据全在FFD9文件尾之后,并且标有part1,part2,part3



按照顺序合并数据块,得到压缩包。密码和刚刚爆破的密码一样,1234。此时可以得到flag.txt了

flag.txt内容:
G&eOhGcq(ZG(t2*H8M3dG&wXiGcq(ZG&wXyG(j~tG&eOdGcq+aG(t5oG(j~qG&eIeGcq+aG)6Q<G(j~rG&eOdH9<5qG&eLvG(j~sG&nRdH9<8rG%++qG%__eG&eIeGc+|cG(t5oG(j~sG&eOlH9<8rH8C_qH9<8oG&eOhGc+_bG&eLvH9<8sG&eLgGcz?cG&3|sH8M3cG&eOtG%_?aG(t5oG(j~tG&wXxGcq+aH8V6sH9<8rG&eOhH9<5qG(<E-H8M3eG&wXiGcq(ZG)6Q<G(j~tG&eOtG%+<aG&wagG%__cG&eIeGcq+aG&M9uH8V6cG&eOlH9<8rG(<HrG(j~qG&eLcH9<8sG&wUwGek2)hint里提示了 0x10,0x20,0x30,0x55。转化成十进制即为:16 32 48 85。16 32 85都能明白,这个48我感觉是出题的时候不小心写错了。
解码过程:
base85:
475532444B4E525549453244494E4A57475132544B514A54473432544F4E4A5547515A44474D4A5648415A54414E4257473434544B514A5647595A54514D5A5147553444474D5A5547453355434E5254475A42444B514A57494D3254534D5A5447555A444D4E5256494532444F4E4A57475A41544952425547343254454E534447595A544D524A5447415A55493D3D3Dbase16:
GU2DKNRUIE2DINJWGQ2TKQJTG42TONJUGQZDGMJVHAZTANBWG44TKQJVGYZTQMZQGU4DGMZUGE3UCNRTGZBDKQJWIM2TSMZTGUZDMNRVIE2DONJWGZATIRBUG42TENSDGYZTMRJTGAZUI===base32:
54564A4456455A3757544231583046795A5638305833417A636B5A6C593352665A47566A4D47526C636E303Dbase16:
TVJDVEZ7WTB1X0FyZV80X3AzckZlY3RfZGVjMGRlcn0=base64:
MRCTF{Y0u_Are_4_p3rFect_dec0der}我爱Linux
下载得到一张png图片,查看winhex头数据块和尾文件可知,其实是JPG文件,将头文件修改为FFD8FF,即可得到正确图片。
在FFD9后面有一堆不是图片的数据块:

通过百度可知这是python的序列化,可以利用pickle库进行反序列化。现在装python的时候会自带安装这个库,可以直接使用。
反序列化脚本:
import pickle
fp = open("1.txt","rb+")
fw = open('pickle.txt', 'w')
a=pickle.load(fp)
pickle=str(a)
fw.write( pickle)
fw.close()
fp.close()可以获得一些类似坐标的数据:

利用以下脚本跑一下即可获得flag:
fw = open("pickle.txt","r")
text=fw.read( )
i=0
a=0
while i<len(text)+1:
if(text[i]==']'):
print('\n')
a=0
elif(text[i]=='('):
if(text[i+2]==','):
b=text[i+1]
d=text[i+1]
b=int(b)-int(a)
c=1
while c<b:
print(" ", end="")
c += 1
print(text[i+5], end="")
a=int(d)
else:
b=text[i+1]+text[i+2]
d=text[i+1]+text[i+2]
b=int(b)-int(a)
c=1
while c<b:
print(" ", end="")
c += 1
print(text[i+6], end="")
a=int(d)
i +=1
最终观察以下即可得到flag:
flag{a273fdedf3d746e97db9086ebbb195d6}(所以到最后我还是不知道和linux有什么关系....)
[GUET-CTF2019]soul sipse
下载得到一个音频文件,听一下非常的刺耳,但是并不是摩斯电码。波形和频谱也没看出什么,binwalk也分离不出东西。于是尝试steghide,密码为空,分离出了一个download.txt。

download.txt里是一个下载连接:
https://share.weiyun.com/5wVTIN3下载得到一张打不开的png图片,用winhex打开查看数据

png文件的头文件是 89 50 4E 47,这里头文件出错了。修改头文件后得到图片

利用unicode解码,得

得到两个数字,但不知道这两个数字的意义是啥。
重新回到频谱图,把采样频率调为22050hz,能看到如何得到flag
以前虽然我也看波形,但从来没调过采样频率,这次也学到了点东西

4070+1234=5304 所以最后flag为:
flag{5304}
[HDCTF2019]你能发现什么蛛丝马迹吗
下载下来得到一个128MB的img文件,估计是个内存取证题。

确实是内存取证,但是采用profile=Win2003SP0x86的时候有问题,分析不了内存文件

于是尝试Win2003SP1x86,就可以了。

先范围式的查看一下有无flag文件,我这里尝试了一下filescan txt和png文件,后发现有一个png图片,利用dumpfiles分离出来,得到一个二维码

扫码得到一个密文,尝试base64,但是是乱码,于是再回到内存文件里看看。

利用cmdscan发现有一些奇怪的数据
volatility -f memory.img --profile=Win2003SP1x86 cmdscan

DumpIt.exe有一定的数据,于是尝试把DumpIt.exe分离出来:
在之前的pstree中可以看到DumpIt的PPID是1992
volatility -f memory.img --profile=Win2003SP1x86 memdump -p 1992 -D ./
然后利用foremost -T 1992.dmp,得到文件,其中也包括了之前得到的png文件

有key有iv,尝试AES解密,最终得到flag:

[UTCTF2020]File Carving
binwalk可以分离出一个压缩包,压缩包里有一个ELF文件。搜索flag,可以找到flag,但是乱码了

然后丢到IDA里找,也找不到flag。之后才知道,ELF也是linux的可执行文件,可以直接在linux中执行,跑一下即可得到flag

[ACTF新生赛2020]music
利用QQ音乐打开,提示文件错误。自己生成了一个m4a文件分析了一下,发现头文件都是00 00 00

然而题目下载下来的文件却是A1 A1 A1
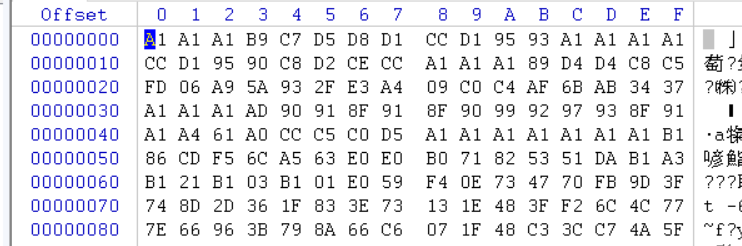
然后这是我想到了两种可能的解题方法,一种是把所有的A1转化成00,一种是把整个文件利用异或,把A1转化成00。我先尝试了一下异或,利用010editor对A1进行异或操作,即可得到正确音频

记得的音频播放一遍即可获得flag:
actf{abcdfghijk}