[toc]
第二部分的BUUCTF难题,由于分值>90的题目比较难,每道题都需要写挺多的wp,所以新开一篇文章继续记录一下这部分的题目。也易于自己整理。
[RoarCTF2019]davinci_cipher
下载附件得到一个流量包和一个flag.txt,
flag.txt里的数据很明显是unicode编码可以利用此网站解密:
https://r12a.github.io/app-conversion/
U+1F643U+1F4B5U+1F33FU+1F3A4U+1F6AAU+1F30FU+1F40EU+1F94BU+1F6ABU+1F606U+1F383U+1F993U+2709U+1F33FU+1F4C2U+2603U+1F449U+1F6E9U+2705U+1F385U+2328U+1F30FU+1F6E9U+1F6A8U+1F923U+1F4A7U+1F383U+1F34DU+1F601U+2139U+1F4C2U+1F6ABU+1F463U+1F600U+1F463U+1F643U+1F3A4U+2328U+1F601U+1F923U+1F3A4U+1F579U+1F451U+1F6AAU+1F374U+1F579U+1F607U+1F374U+1F40EU+2705U+2709U+1F30FU+23E9U+1F40DU+1F6A8U+2600U+1F607U+1F3F9U+1F441U+1F463U+2709U+1F30AU+1F6A8U+2716
解得:
????????????✉??☃??✅?⌨????????ℹ???????⌨???????????✅✉?⏩??☀????✉??✖
但是base100和emoji爆破都没用,先看流量包。
分析一下流量包,中间有一段usb流量。还有很多其他流量,不过在这一题当中重点在usb流量,其他流量都跟题目无关。一般遇到有usb流量的题目,usb流量都是重点。
搜索关键词:DESCRIPTOR
可以发现包含了DEVICE的信息

得到此设备的信息:Wacom PTH-660,百度可知是一种数位板。

tshark分离下usb流量
tshark -r k3y.pcapng -T fields -e usb.capdata | sed '/^\s*$/d' > usb.txt观察到绝大多数都是27字节长度的数据,少部分其他的。可知27字节的数据应该就是数位板的画图数据。将非27字节长度的数据手动删掉,留下的即为有效数据。
而一般有效字节都是不同的,这题的流量不同的字节主要是第3、4、6、7、9字节
其余的应该都与解题无关
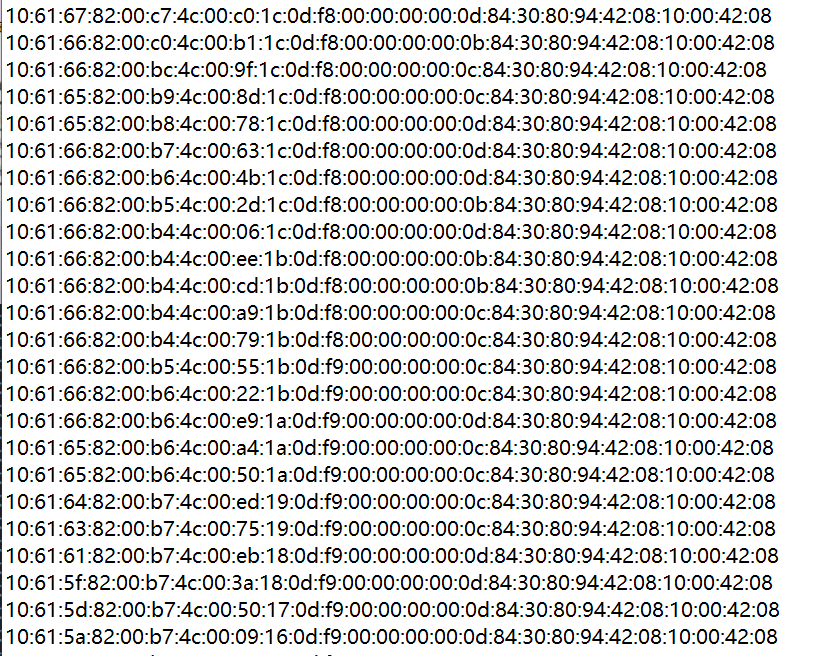
因为自己使用过数位板,所以比较熟悉,数位板本身具有压感,而此数位板的流量正好以00隔断,一个横坐标,一个纵坐标,一个压感信息。
可知x坐标储存在3 4字节,纵坐标储存在6 7字节,压感信息储存在第9个字节,如果为00则是数位笔没有压下去,不画图。
且横纵坐标并不是一般的大端序,而是小端序储存方法,
例如66 82,实际大小是int(8266, 16),而不是一般的int(6682,16)
脚本一把梭,由于图片宽高太大,就不用python画图了,而利用gnuplot画图。所以将数据保存为gnuplot可识别形式。
f = open('out.txt','r')
fi = open('xy.txt','w')
while 1:
a = f.readline()
if not a:
break
a = a.strip('\n')
if a[24:26] != '00':
x = int(a[6:8],16) + int(a[9:11],16)*256
fi.write(str(x))
fi.write(' ')
y = int(a[15:17],16) + int(a[18:20],16)*256
fi.write(str(y))
fi.write('\n')
fi.close()
然后利用gnuplot画图, plot "xy.txt"
得到:
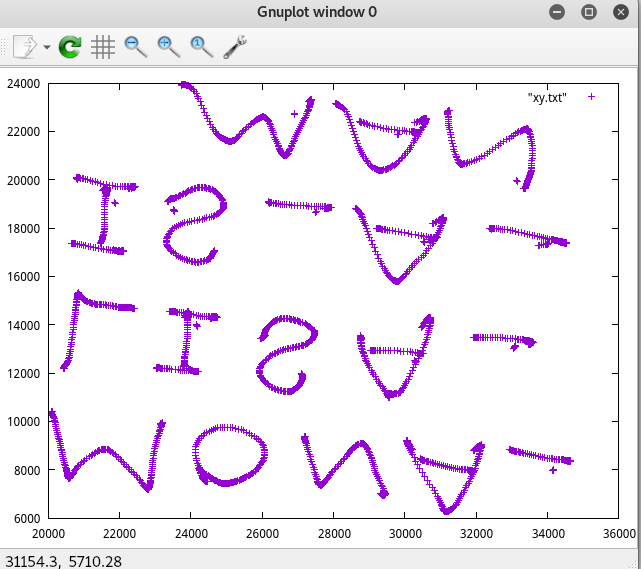
图片垂直翻转一下:

得到字符串:MONA_LISA_IS_A_MAN
根据前面的emoji字符串,需要密钥的emoji我印象中只有emoji-aes了。尝试将画图得到的key用来解emoji-aes
https://aghorler.github.io/emoji-aes/#
解得flag:
RoarCTF{wm-m0de3n_dav1chi}一路到底
下载附件得到155534个txt文件,其中有一个是start.txt。
打开发现:
20555 : The next is a8242a234560a0d3cf121864ee34d7fb.txt然后尝试搜索 a8242a234560a0d3cf121864ee34d7fb.txt,并打开:
772 : The next is 5d2ecc80d506dc00c6457a2cb6430d54.txt猜测需要重复执行上述操作,写个脚本跑一遍:
path = 'C:/Users/34603/Desktop/38ff11ef-e3d3-4f8a-b163-3d300bc016ea/files/'
name = 'start.txt'
while 1:
file_name = path + name
f = open(file_name, 'r').read()
print(f)
name = f.split(' : ')[1].replace('The next is ', '')最后得到:
End !并没有flag相关的东西。这时想到了每个txt文件里开头都有一串数字,start.txt里的数字为 20555,尝试转化为16进制,得到 504b,正好就是压缩包文件的文件头。可知这个方向应该是对的,写个脚本跑一遍:
import struct
path = 'C:/Users/34603/Desktop/38ff11ef-e3d3-4f8a-b163-3d300bc016ea/files/'
name = 'start.txt'
res = open('C:/Users/34603/Desktop/res.zip', 'wb')
while 1:
file_name = path + name
f = open(file_name, 'r').read()
print(f)
name = f.split(' : ')[1].replace('The next is ', '')
num = f.split(' : ')[0]
num = int(num, 10)
num_hex = str("{:#06X}".format(num))[2:]
num_hex1 = num_hex[:2]
num_hex2 = num_hex[2:]
#print(num_hex)
s1 = struct.pack('>B',int(num_hex1,16))
s2 = struct.pack('>B',int(num_hex2,16))
s = s1 + s2
#print(s)
res.write(s)得到一个加密的压缩包,并且有一个注释:
年轻人,能走到这一步不容易啊!不要灰心,密码十分钟就可以破解哦,加油!爆破一下,得到密码: tgb678
得到一个png图片但是打不开,用winhex打开查看一下,发现后面的数据并不是png的数据,而是jpg的数据。将头文件改成FFD8FFE0,成功打开图片。
最终得到flag:
